概要
にゃんぱすーボタン のカウントの推移を表示する非公式の webサイト をつくりました。 すべて AWS のサービス上で動いています。 Lambda関数を一定時間ごとに呼び出してカウントを取得し、S3バケットにその値とグラフ画像を保存して、S3 でホストしているサイトから参照しています。
はじめに
にゃんぱすーボタン という webサイトがあります。 このサイトに設置してあるボタンをクリックすると、グローバルなカウントを1ずつ増やすことができます。 いまも日々、カウンターは進んでいます。
カウントの値はある API で取得できます。 「こっそり」公開されているのでここでも明示はしませんが、探せば見つかります。
今回、この API を一定時間ごとに呼び、記録したカウントの推移をグラフで表示する非公式の webサイト をつくりました。 このサイトはすべて AWS のサービス上で動いており、具体的には主に Lambda と S3 を使っています。
この記事では、この webサイトの仕組みを簡単に説明します。
全体構成
全体の構成は以下のようになっています。 Lambda関数は Python 3.6 で実装しました。
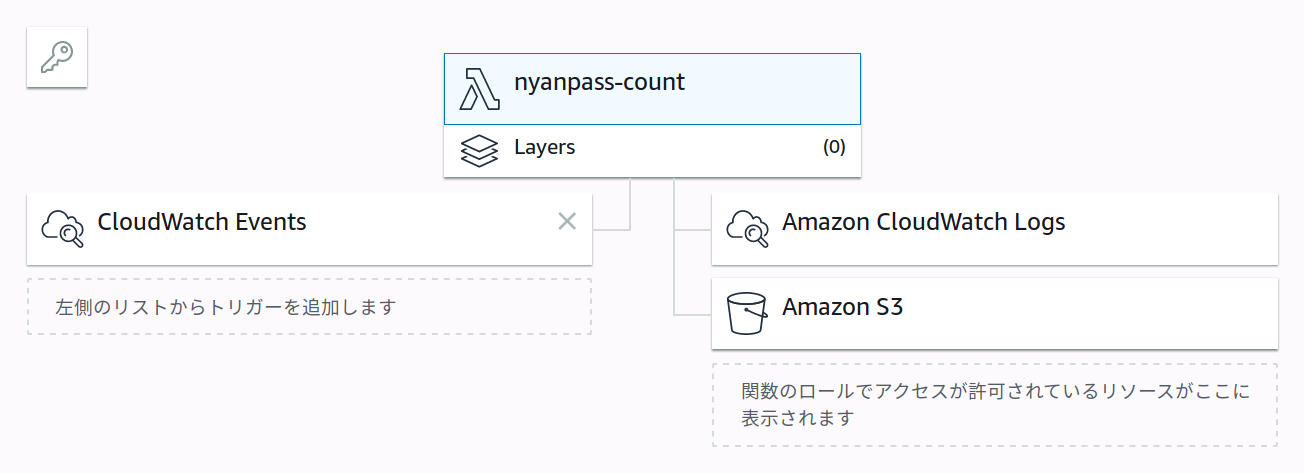
およそ次の流れで動いています。
- CloudWatch Events が一定時間ごとに Lambda関数を呼び出す。
- Lambda関数が、
- 「にゃんぱすーボタン」からカウントを取得する。
- S3バケットに保存してある過去のデータを実行環境のストレージにダウンロードし、新しいカウントを結合する。
- 全体のデータをグラフ化し画像ファイルとしてストレージに保存する。
- 新しいカウントと画像を S3バケットにアップロードする。
- S3バケットでホストしている webサイトが画像を参照する。
Lambda関数を一定時間ごとに呼び出す
CloudWatch Events を用いると、Lambda関数を予め定めたスケジュールで起動できます。
新しいトリガーを作り、ルールタイプを「スケジュール式」に設定します。 今回はスケジュール式に cron を用い、一定時間ごとに呼び出すようにしました。
cron(0 * * * ? *)と記述すれば一時間ごとに起動します。
Lambda関数内でファイルを扱う
Lambda関数の実行環境では、一時作業用のストレージとして /tmp ディレクトリが使えます。
S3 からダウンロードしたファイルや、生成したグラフ画像はここに一時保存しました。
os.path.join(os.sep, "tmp", uuid4().hex)などで一意なファイル名を生成するとよいでしょう。
S3 にアップロード、S3 からダウンロードする
Python用の AWS SDK として Boto3 を使いました。
Boto3 は Lambdaランタイムに組み込まれているため、import boto3 するだけで使えます。
具体的な使いかたは Boto3公式ドキュメント を参照してください。
Lambda関数のロールに、対象となる S3バケットへアクセスできる権限を付与しておきましょう。
外部 Pythonモジュール (pandas, Matplotlib) を使う
参考:AWS公式ドキュメント
今回の実装では、データ整理に pandas を、グラフ化に Matplotlib を使っています。 これら外部モジュールは Lambdaランタイムに組み込まれていないため、そのままインポートはできません。 Lambda関数のデプロイパッケージに含める必要があります。
まず、ローカルの開発用ディレクトリにすべての依存モジュールをインストールします。 これは
$ pip install pandas -t ./vendorのように、-t(または --target)オプションでインストール先ディレクトリを指定することでできます。
Lambda関数スクリプトがあるディレクトリ直下に外部モジュールを置くと汚くなるので、今回は vendorディレクトリを作り、そこにインストールしました。
つまり、以下のような構成です。
.
├── lambda_function.py
└── vendor
├── pandas
├── matplotlib
...vendor ディレクトリをインポートパスに追加するため、以下のコードを Lambda関数スクリプト (lambda_function.py) の初めに追記します。
import os
import sys
sys.path.append(
os.path.join(os.path.abspath(os.path.dirname(__file__)), "vendor"))次に、スクリプトと依存モジュールを zip に固め、デプロイパッケージを作成します。
$ zip -r lambda.zip lambda_function.py vendorこのデプロイパッケージを直接あるいは S3バケットを経由して Lambda関数としてアップロードします。 pandas と Matplotlib を含めるとパッケージサイズは 30MB を超えます。
ちなみに、依存モジュールを S3バケットにおいておき、Lambda関数が起動するごとにダウンロードしてきて動的にインポートすることも可能なようです。 こうするとパッケージサイズが小さくなり、スクリプトをインラインで編集できるようになりそうです。
S3 で静的サイトをホストする
参考:AWS公式ドキュメント
S3 を使って静的webサイトをホスティングし公開することができます。 今回は、グラフ画像が保存されているバケットに簡単な HTMLファイルを置き webサイトとしています。 独自ドメインは使いません。
まず、バケットの「プロパティ」から “Static website hosting” を有効にします。 HTMLファイルの名前を「インデックスドキュメント」に指定します。
次に、webサイトの読み取り操作ができるよう、「アクセス権限」からバケットポリシーを設定してパブリックアクセス権限を指定します。
index.html と画像ファイルを公開する場合、次のように記述します(バケット名は適宜書き換えてください)。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": [
"arn:aws:s3:::bucket-name/index.html",
"arn:aws:s3:::bucket-name/*.png"
]
}
]
}Lambda関数が失敗したときにアラームを送る
Lambda関数でエラーが発生したときにアラームが送られるように設定します。
CloudWatch でアラームを作成し、メトリクスを「エラー > 0 」と設定しました。 また、何らかの理由で Lambda関数が起動しなかったときのため、データの欠落も不正な状態とみなしています。 今回は、アラームの送り先を自分のメールアドレスにしました。
まとめ
にゃんぱすーボタン のカウントの推移を表示する非公式の webサイト をつくりました。 AWS Lambda関数を一定時間ごとに起動してカウントを取得し、グラフ画像を生成して S3バケットでホストした webサイトから参照しています。
ちなみに、『のんのんびより』を見たことはありません。